Data Modeling for Marketing ออกแบบฐานข้อมูลให้ฉลาด เพื่อการตลาดที่เหนือกว่า : [MarTech Basic ep.32]
martech-basic 30 Nov 2025
Author : superadmin

ในโลกของการตลาดดิจิทัล เรามีข้อมูลลูกค้ามากมายมหาศาล ทั้งข้อมูลการคลิก, การซื้อ, การแชท, การเปิดอีเมล, หรือการใช้งานแอปฯ ปัญหาไม่ได้อยู่ที่ว่า “มีข้อมูลมากพอหรือไม่” แต่อยู่ที่ว่า “ข้อมูลเหล่านั้นถูกจัดเก็บและเชื่อมโยงกันอย่างมีระบบหรือเปล่า?”
💡 ทำไมมีข้อมูลเยอะ แต่ใช้จริงไม่ได้ ?
เปรียบเทียบง่ายๆ ลองนึกภาพห้องสมุดที่มีหนังสือกองรวมกันอยู่บนพื้น แม้จะมีหนังสือล้ำค่ามากมาย แต่ก็ไม่มีใครหามันเจอเพื่อนำไปใช้ประโยชน์ได้ ในทำนองเดียวกัน หากข้อมูลลูกค้าถูกเก็บแบบกระจัดกระจาย หรือไม่มีการกำหนดโครงสร้างที่ชัดเจน (Schema) มันก็จะไร้ค่าทันทีเมื่อต้องการนำไปวิเคราะห์ หรือสร้างแคมเปญการตลาดแบบอัตโนมัติ (Automation) ที่ซับซ้อน
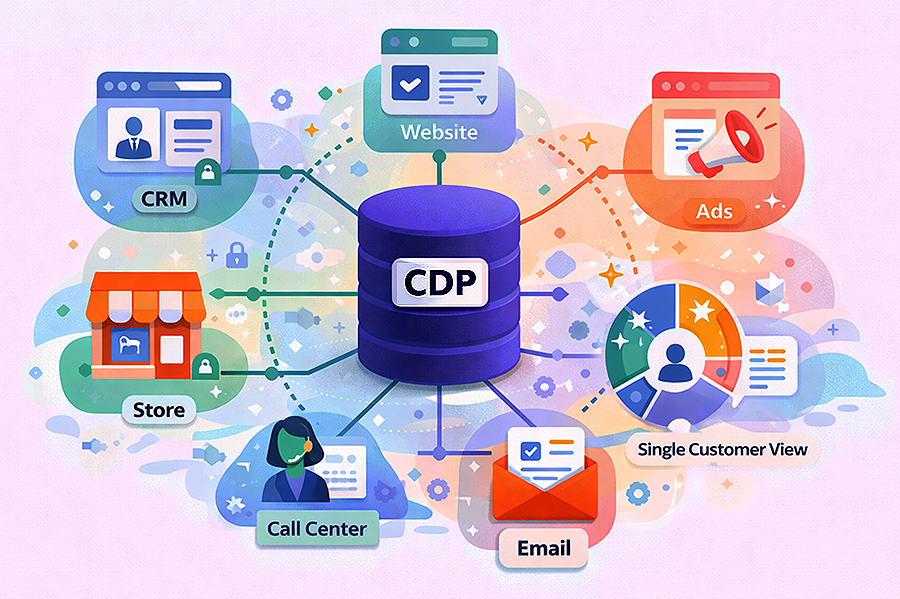
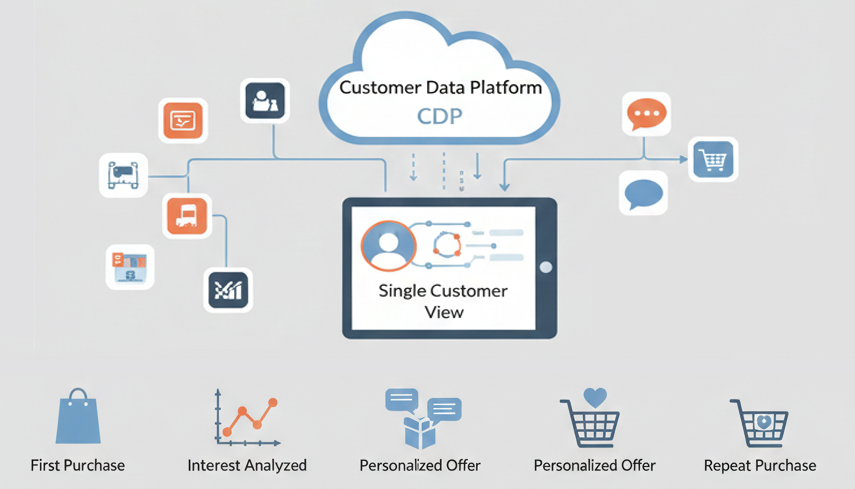
นี่คือเหตุผลที่ Data Modeling (การออกแบบโครงสร้างข้อมูล) กลายเป็นรากฐานสำคัญที่ไม่ควรมองข้ามสำหรับนักการตลาดในยุคปัจจุบัน โดยเฉพาะอย่างยิ่งในการทำงานกับ Customer Data Platform (CDP) มันคือการออกแบบพิมพ์เขียวให้ข้อมูลพูดคุยกันได้ เพื่อตอบโจทย์การตลาดที่แม่นยำและว่องไว
🎯 Data Modeling คืออะไร และทำไมต้องทำเพื่อการตลาด?
Data Modeling คือ กระบวนการวาดแผนผังหรือพิมพ์เขียวเพื่อกำหนดว่า ข้อมูลประเภทไหนจะถูกจัดเก็บอย่างไร และ ข้อมูลเหล่านั้นมีความสัมพันธ์เชื่อมโยงกันอย่างไร ภายในฐานข้อมูลหรือ CDP
จากนั้นก็กำหนดเป้าหมายหลักของการทำ Data Modeling 2 ข้อใหญ่ คือ …
- ✅ ตอบโจทย์การวิเคราะห์ (Analytics):
ช่วยให้นักวิเคราะห์สามารถดึงข้อมูลที่เชื่อมโยงกันมาคำนวณหาตัวชี้วัดสำคัญ ๆ ได้ง่าย เช่น “ลูกค้าที่ซื้อสินค้า X มีพฤติกรรมการเปิดอีเมลอย่างไรก่อนตัดสินใจซื้อ?” - 🚀 ตอบโจทย์การดำเนินการ (Campaign Automation):
ช่วยให้ระบบการตลาดอัตโนมัติ (Marketing Automation) สามารถสร้างเงื่อนไขที่ซับซ้อนได้ทันที
เช่น “ส่งคูปองส่วนลด 10% ให้ลูกค้าที่เคยดูสินค้า A แต่ยังไม่เคยซื้อ และ เป็นสมาชิกมานานกว่า 6 เดือน และ อยู่ในกรุงเทพฯ”
💡 แกนหลักของ Data Modeling: 3 องค์ประกอบสำคัญ
ทุกโมเดลข้อมูลการตลาดที่ดีต้องประกอบด้วยข้อมูล 3 ส่วนหลัก และความสัมพันธ์ระหว่างกัน:
- 1. 👤 ข้อมูลลูกค้า (Customer/Identity Data): ข้อมูลส่วนตัว, ข้อมูลติดต่อ, ID ลูกค้า, สถานะสมาชิก (Static Data)
- 2. 🛒 ข้อมูลธุรกรรม (Transactional Data): รายละเอียดการซื้อ, ใบเสร็จ, มูลค่าการสั่งซื้อ, สถานะการชำระเงิน (Specific Event Data)
- 3. 🏃 ข้อมูลพฤติกรรม (Behavioral Data): การคลิก, การเข้าชมเว็บไซต์, การดูวิดีโอ, การเปิด/ปิดอีเมล (Interaction Event Data)

⚙️ ส่วนประกอบของโมเดลข้อมูล: Schema และ Relationship ในการออกแบบ Data Model เราจะใช้เครื่องมือหลัก 2 อย่างคือ Schema และ Data Relationships
1. 📝 การออกแบบ Schema (โครงสร้างข้อมูล)
Schema (สกีมา) คือการกำหนดว่าตารางข้อมูลแต่ละตารางควรมี “คอลัมน์” หรือ “ช่องข้อมูล” อะไรบ้าง และแต่ละช่องนั้นเป็นข้อมูลประเภทไหน
⭐️ ตัวอย่างการออกแบบ Schema สำหรับตารางลูกค้า (Customer Table):
| คอลัมน์ (Field) | ประเภทข้อมูล (Data Type) | เหตุผลทางการตลาด (Marketing Use) |
customer_id | Text/String (Primary Key) | 🔗 ใช้เชื่อมโยงกับตารางอื่น ๆ ทั้งหมด (หัวใจหลัก) |
first_name | Text/String | 📧 ใช้ในการปรับอีเมลส่วนบุคคล (Merge Tag) |
lifetime_value_segment | Text/String | 📊 ใช้แบ่งกลุ่มลูกค้า VIP (High-Value Targeting) |
last_purchase_date | Date/Timestamp | 📅 ใช้ในการกำหนดแคมเปญลูกค้าที่ไม่ใช้งาน (Win-back Campaign) |
opt_in_email | Boolean (True/False) | 🛑 ใช้ในการตรวจสอบสิทธิ์การส่งอีเมล (PDPA Compliance) |
2. 🔗 การกำหนดความสัมพันธ์ของข้อมูล (Data Relationships)
การตลาดมักใช้โมเดลข้อมูลแบบ Star Schema หรือ Snowflake Schema ซึ่งมีความสัมพันธ์ระหว่างข้อมูล 3 ประเภทหลัก:
- Primary Table (ตารางหลัก): คือตารางลูกค้า (Customer Table) ที่มี
customer_idเป็นกุญแจหลัก - Fact Tables (ตารางเหตุการณ์): คือตารางที่บันทึกเหตุการณ์ที่เกิดขึ้นบ่อยครั้ง (เช่น การซื้อ, การคลิก) โดยจะมีคีย์รอง (Foreign Key) ที่เชื่อมโยงกลับไปหาตารางลูกค้าเสมอ
- ตัวอย่าง: ตารางธุรกรรม (Transaction), ตารางการเปิดอีเมล (Email Open Event)
🧠 ประเภทของความสัมพันธ์ที่ใช้บ่อย :
| ความสัมพันธ์ | คำอธิบาย | ตัวอย่างการใช้งานทางการตลาด |
| 1:1 (หนึ่งต่อหนึ่ง) | ลูกค้า 1 คน มีข้อมูลนั้นได้เพียง 1 ชุดเท่านั้น | 👤 ลูกค้า 1 คน มีโปรไฟล์ SCV ได้เพียง 1 โปรไฟล์ |
| 1:Many (หนึ่งต่อมาก) | ลูกค้า 1 คน สามารถมีข้อมูลนั้นได้หลายชุด | 🛒 ลูกค้า 1 คน สามารถมีคำสั่งซื้อได้หลายรายการ |
| Many:Many (มากต่อมาก) | ข้อมูลทั้งสองเชื่อมโยงกันได้หลายชุด | 📌 ลูกค้าหลายคนสามารถเข้าร่วมแคมเปญหลายแคมเปญได้ |
🚀 Data Modeling เพื่อ Campaign Automation ที่ล้ำหน้า
การออกแบบโครงสร้างข้อมูลที่ดีจะช่วยให้เราสร้างเงื่อนไขของแคมเปญอัตโนมัติที่ซับซ้อนได้อย่างง่ายดาย โดยไม่จำเป็นต้องเขียนโค้ดซ้ำ ๆ
1. ⏰ การสร้าง Trigger ที่แม่นยำ (Precision Triggering)
เมื่อ Schema ถูกออกแบบให้มีตารางเหตุการณ์ (Fact Tables) ที่ชัดเจน ระบบ Automation จะสามารถตรวจสอบเงื่อนไขได้ทันทีเมื่อเหตุการณ์เกิดขึ้น:
- ตัวอย่างที่ 1 (Abandoned Cart): โมเดลข้อมูลมีการบันทึกเหตุการณ์
add_to_cart_eventและpurchase_eventการ Automation จะทำงานก็ต่อเมื่อมีadd_to_cart_eventแต่ไม่มีpurchase_eventภายใน 1 ชั่วโมง โดยการใช้customer_idเป็นตัวเชื่อม - ตัวอย่างที่ 2 (Lifecycle Stage Change): เมื่อค่าในคอลัมน์
last_purchase_date(ใน Customer Table) ถูกอัปเดตเกิน 90 วัน ระบบจะย้ายลูกค้าไปกลุ่มChurn Riskทันที และสั่งให้ส่งชุดอีเมล Win-back Campaign
2. 🤝 การทำ Lead Scoring ที่เป็นประโยชน์
การกำหนด Score ให้ลูกค้าตามความสนใจต้องใช้ข้อมูลจากหลายตาราง การออกแบบที่เชื่อมโยงกันทำให้การคำนวณง่ายขึ้น:
- สูตร Scoring แบบง่าย: (จำนวนการเข้าชมหน้า Pricing ใน 7 วัน x 5 คะแนน) + (จำนวนการคลิกลิงก์ในอีเมล x 2 คะแนน) + (การดาวน์โหลดเอกสาร X x 10 คะแนน)
- ผลลัพธ์: หากลูกค้ามีคะแนนเกิน 50 คะแนน ระบบจะสั่งให้ทีมขายติดต่อ หรือส่งข้อเสนอพิเศษผ่าน LINE OA (Activation) ทันที ซึ่งนี่คือการเปลี่ยนข้อมูลดิบให้เป็น “โอกาสทางธุรกิจ”
3. 💾 การจัดการข้อมูลที่พร้อมใช้งาน (Actionable Data)
CDP จะใช้ Data Model นี้ในการสร้าง Attributes หรือ Properties ใหม่ ๆ ที่พร้อมใช้งานทันทีโดยไม่ต้องคำนวณซ้ำ:
- Attribute ที่สร้างใหม่ :
- “Recency Score”: (ความถี่ในการซื้อล่าสุด)
- “Preferred Channel”: (ช่องทางที่ลูกค้ามีการตอบสนองสูงที่สุด เช่น Email, LINE)
- “Top Category Interest”: (หมวดหมู่สินค้าที่ลูกค้าดูบ่อยที่สุดใน 30 วันล่าสุด)
- “Recency Score”: (ความถี่ในการซื้อล่าสุด)
- ประโยชน์: ทีมการตลาดสามารถใช้ Attribute เหล่านี้ในการสร้างแคมเปญได้โดยตรง เช่น “ส่งแคมเปญนี้ผ่าน Preferred Channel ของลูกค้าเท่านั้น” ซึ่งช่วยประหยัดงบประมาณและเพิ่มประสิทธิภาพ
🛑 ความท้าทายในการออกแบบ Data Model สำหรับนักการตลาด
การออกแบบโมเดลข้อมูลมักมีอุปสรรคที่นักการตลาดต้องตระหนักถึง:
- 1. 🧩 Data Standardization (การกำหนดมาตรฐานข้อมูล): ข้อมูลที่มาจากหลายระบบมักมีรูปแบบที่แตกต่างกัน (เช่น ชื่อจังหวัดเขียนไม่เหมือนกัน) องค์กรต้องลงทุนในการทำ Data Cleaning และกำหนดมาตรฐานให้ข้อมูลทั้งหมดมีรูปแบบเดียวกันก่อนเข้า CDP
- 2. 🔄 Dealing with Change (การรองรับการเปลี่ยนแปลง): ธุรกิจมีการเพิ่มช่องทางใหม่ ๆ (เช่น TikTok, Threads) อยู่เสมอ Data Model ที่ดีต้องมีความยืดหยุ่น (Flexible) พอที่จะรองรับการเพิ่มตารางเหตุการณ์ใหม่ ๆ ได้ในอนาคต โดยไม่จำเป็นต้องรื้อโครงสร้างทั้งหมด
- 3. 🤝 Collaboration (การทำงานร่วมกัน): การออกแบบ Data Model เป็นงานที่ต้องทำร่วมกันระหว่าง นักการตลาด (ผู้กำหนด Use Case) และ ทีม IT/Data Engineer (ผู้สร้างระบบและโครงสร้าง) การสื่อสารและกำหนดความต้องการตั้งแต่ต้นจึงเป็นสิ่งสำคัญที่สุด
🏁 สรุป: Data Modeling คือการลงทุนระยะยาวของนักการตลาด
Data Modeling คือการสร้างพิมพ์เขียวที่กำหนดชะตาชีวิตของแคมเปญการตลาดทั้งหมด มันคือการเปลี่ยนข้อมูลที่กระจัดกระจายให้เป็นสินทรัพย์ที่มีโครงสร้างและสามารถใช้งานได้อย่างแท้จริง (Actionable)
สำหรับธุรกิจในยุคที่ต้องการความว่องไวแบบ Agile Marketing และความแม่นยำแบบ Personalization การลงทุนในการออกแบบ Schema และความสัมพันธ์ของข้อมูลอย่างรอบคอบในฐานข้อมูลหรือ CDP จะช่วยให้:
- 🚀 ความเร็วเพิ่มขึ้น: ลดเวลาในการเตรียมข้อมูลสำหรับการวิเคราะห์จากสัปดาห์เป็นนาที
- 💰 ROI สูงขึ้น: แคมเปญ Automation ทำงานได้แม่นยำและถูกจังหวะเวลามากขึ้น
- 🤝 ความเข้าใจลูกค้าลึกซึ้งขึ้น: เห็นภาพรวมของลูกค้าเดียว (SCV) ที่ครบถ้วนสมบูรณ์
การออกแบบ Data Model ที่ดีจึงไม่ใช่แค่เรื่องของเทคนิค แต่เป็น กลยุทธ์สำคัญ ที่แยกความแตกต่างระหว่างแบรนด์ที่สามารถขับเคลื่อนด้วยข้อมูลได้อย่างเต็มประสิทธิภาพ กับแบรนด์ที่ยังคงติดอยู่ในกองข้อมูลที่ไม่มีใครใช้งานได้จริง
. : รู้จัก PAM Realtime CDP ซอฟต์แวร์การตลาดอัตโนมัติและ CDP ไทย ที่ PAMs.ai : .
Share :
Start using PAM today
Reach every customer steps, make every action count.
Related Blogs